
AMD正式发布代号Gorgon Halo的Ryzen AI Max 400系列处理器,这是前代300系列的小幅迭代,却在客户端AI领域扔下一颗重磅炸弹:它成为全球首款能本地运行300B参数大模型的x86客户端芯片。本地运行超大模型的时代,比所有人预想的来得更早。这一次AMD靠的不是架构革命,而是内存容量的突破,这背后藏着怎样的行业逻辑变化?

AMD Ryzen AI Max 300和400系列处理器芯 · 展示两代Ryzen AI Max系
不是架构革命 是内存的决定性突破
很多人看到发布信息第一反应是:又是小幅迭代,架构没变,频率只提了0.1GHz,没什么新意。可偏偏被大多数人忽略的内存升级,才是这次发布真正的破局点。
前代Ryzen AI Max 300系列旗舰最高支持128GB统一内存,最多可分配96GB作为显存,已经能支持数百亿参数大模型本地运行。而新一代400系列直接把上限拉到了192GB统一内存,可分配给显存的容量更是飙升到160GB,足足增加了67%。
统一内存架构的核心优势,本来就是CPU、GPU、NPU可以共享同一个内存池,不需要在不同芯片之间反复搬运数据,减少延迟浪费。这次容量突破后,原本需要云端集群才能运行的300B参数大模型,现在可以直接塞进单颗客户端处理器的内存里。
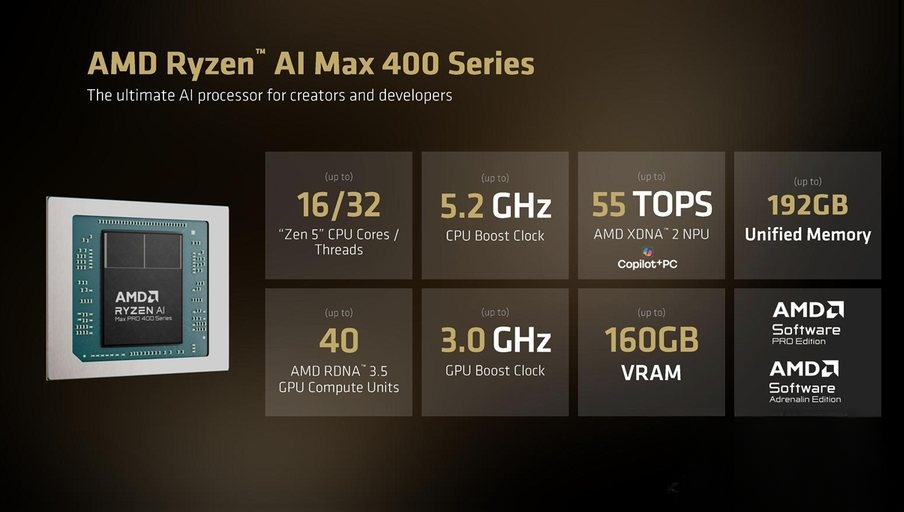
AMD Ryzen AI Max 400系列处理器及参数 · 呈现该系列处理器核心规格参数
这不是简单的参数数字游戏,而是整个本地AI开发逻辑的改变。在此之前,x86客户端平台的内存上限一直卡在128GB,想要运行更大参数的模型只能依赖云端服务,开发者不仅要承担高额的云服务成本,还要面对数据传输延迟和隐私风险。
AMD官方算了一笔账:一台锐龙AI Halo开发主机,每月可以帮开发者节省750美元的云服务支出。按这个计算,不到半年就能赚回主机本身的成本。
为什么是AMD先摸到192GB这个门槛
整个行业都在做AI处理器,为什么偏偏是AMD先在客户端实现了192GB统一内存支持?答案其实藏在产品定位里。
大多数PC处理器厂商,还是把AI功能作为消费级产品的附加卖点,重点优化的是日常AI应用、轻量推理场景,对超大内存的需求并不迫切。而AMD从一开始就把Ryzen AI Max系列定位给创作者和开发者,核心需求就是运行更大的模型、处理更复杂的本地任务。
这次发布还有一个容易被忽略的细节:首批上市的全都是带PRO标识的企业级版本。也就是说,AMD先把产品给到专业开发者和企业用户,验证需求后再推出消费级版本。这种路径选择,其实也反映了AMD对本地AI市场的判断:专业开发者的真实需求,才是驱动技术突破的核心动力。
从规格来看,这次升级确实只是Refresh式的小改:延续Zen 5 CPU架构、RDNA 3.5 GPU架构、XDNA 2 NPU架构,旗舰型号频率只提升了0.1GHz,NPU算力只增加了5TOPS到55TOPS。这种小改反而印证了一个判断:目前的架构已经足够支撑现有应用,瓶颈从来都不在计算性能,而在内存容量。
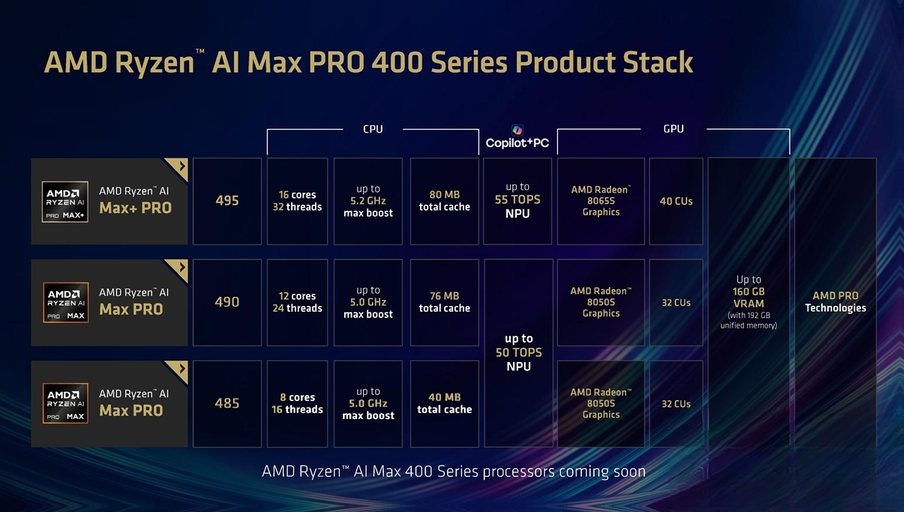
AMD Ryzen AI Max PRO 400系列产品矩阵 · 展示三款不同定位的处理器参数对比
这里其实藏着一个被行业共识忽略的反常识:很多厂商拼命堆NPU算力、升级架构,却忘记了对于本地大模型来说,能放下参数才是第一前提。就算算力再强,内存不够装不下模型,一切都是空谈。这就是这次突破最有价值的地方——AMD戳破了“算力崇拜”的泡沫,重新把内存拉回了核心讨论议题。
三款定位清晰覆盖 专业市场先试水
这次Ryzen AI Max 400系列一口气推出三款PRO版本,覆盖从入门到旗舰的专业计算需求,定位划分非常清晰:
可以看到,只有旗舰型号495获得了全方位的规格升级,包括更高的频率、更多的计算单元和更强的NPU算力,另外两款型号更多是沿用现有规格调整命名,核心的内存支持升级都会跟上。
这种策略其实非常务实:先把旗舰做出来满足最高需求,用中低端型号覆盖更多预算层级的用户。而且所有PRO版本都支持AMD PRO技术,提供企业级的安全性、可管理性和可靠性,也适配专业工作站和商业使用场景的需求。
软件层面也做了区分,同时支持AMD Software PRO Edition和Adrenalin Edition双版本,分别针对专业工作站和高性能创作场景做了优化,兼顾不同用户的使用习惯。
本地AI的爆发点 比我们想的更近
AMD同时确认,下一代锐龙AI Halo迷你开发主机平台,会在今年三季度搭载这款处理器上市,容量升级到192GB,定价3999美元。这个定价乍一看不便宜,但对比每月节省的750美元云成本,其实对开发者来说非常划算。
更值得关注的是,除了AMD自己的开发主机,OEM合作伙伴华硕、惠普、联想都会在今年推出搭载这款处理器的产品,覆盖工作站、迷你PC、高性能笔记本等多种形态。也就是说,这款处理器不是只给少数开发者的定制产品,而是会快速走进大众市场。
本地运行超大模型不再是数据中心的专利,普通开发者用一台PC就能搞定,这件事的影响比大多数人理解的要深远得多。
隐私数据不需要出本地,调试模型不用等云服务器排队,成本一次性投入不需要持续付费,这些优势都会释放大量之前被压抑的需求:很多中小团队和独立开发者,之前因为成本问题不敢碰大模型,现在门槛直接降下来了。
这次升级也给整个行业提了一个醒:AI客户端的竞争,接下来会从拼算力参数转向拼内存容量。谁先解决了大模型的“容纳问题”,谁就能拿到下一轮竞争的主动权。
Zen6架构的Halo版本已经被传取消,AMD选择在现有架构基础上,通过内存扩容满足当前需求,这种务实的选择反而贴合了当前市场的真实节奏。用户不需要等下一场架构革命,现在就能用得上更大的模型,这比什么都重要。
当本地就能跑300B参数大模型,AI开发的游戏规则已经悄悄改变了。云服务不会消失,但会越来越多承担训练和大规模部署的角色,而本地开发、调试、小批量推理的需求,会快速成长起来。最先吃到这波红利的,就是敢提前布局内存突破的玩家。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...