
AI能力越强,落地反而越难——这是过去两年边缘AI市场真实发生的现象。
为什么?与大量从业者的交流后,我们发现了三个主要原因。
核心是模型规模与硬件算力之间的差距。2023年以来,视觉/语言模型、VLA(视觉-语言-动作)模型参数量从几亿跃升到百亿级,模型推理所需算力远超传统嵌入式处理器能提供的范围。“算法跑得动的云端,时延和带宽不允许;能接受时延的边缘,算力和内存带宽又不够”,一位工业自动化从业者说出了这个扎心的事实。
其次,AI芯片的算力虽然在变强,但用好并不容易。NPU从几TOPS涨到几十TOPS,GPU Tensor Core越堆越多,厂商们比拼着标称算力。但这些专用算力真正要用好,面临一些深层挑战,比如不同处理器在执行任务时存在闲置情况,或是工具链的适配、底层驱动的调试等问题,导致纸面算力高,但能调用的实际算力并不理想。
此外还有AI软件栈方面的挑战,生态割裂仍是障碍。为A芯片优化的模型,换到B芯片上效率可能打折,或是需要重新调试代码。软件工具虽强,开发迁移成本却很高。
这也指向一个事实,边缘AI要更好落地,需要一个真正能把模型、硬件、软件能力对齐的平台:算力要能承接得住大模型,且具备协同调度的异构计算能力,同时,软件生态还要给开发者迁移、升级的灵活度。
AMD 锐龙 AI 嵌入式 P100,想重新定义边缘AI算力基准
满足上述需求的方案,会是行业的及时雨,甚至将定义未来几年边缘智能的蓝图。
我们注意到,AMD最新推出的锐龙(Ryzen)AI 嵌入式 P100 系列处理器产品组合,正具备这些特质:它旨在系统性地布局边缘AI市场,提供可扩展的高效 AI 计算能力。
这款处理器具备8至12颗“Zen 5”核心、用于物理 AI 加速的最高可达80 TOPS的系统级算力、用于实时可视化的 AMD RDNA 3.5 图形处理能力,以及基于AMD XDNA 2架构、面向低时延且高能效 AI 推理的神经处理单元(NPU)——而以上所有功能,均集成于一颗芯片中。
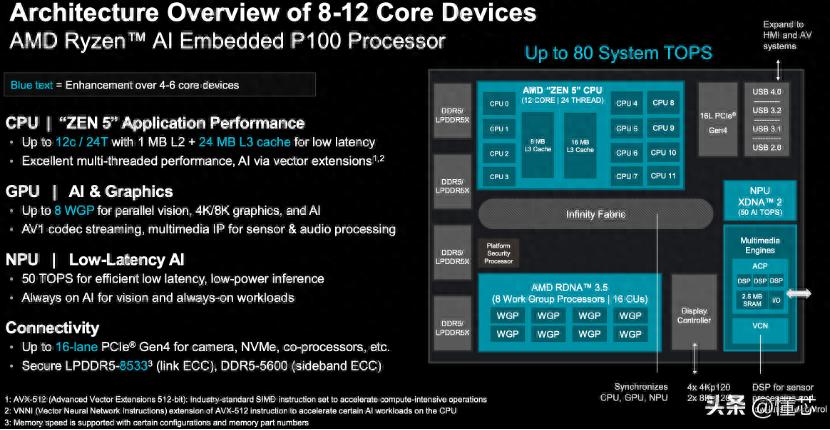
与此前发布的采用相同紧凑型球栅阵列(BGA)封装的 P100 系列处理器相比,新款处理器可提供最高2倍的CPU核心数量、最高8倍的GPU算力,且系统级每秒万亿次运算(TOPS)性能预计提升36%。
与上一代AMD锐龙嵌入式8000系列相比,P100系列预计可提供最高提升39%的多线程性能和最高提升2.1倍的系统级总TOPS。与现有P100系列相比,最新推出的处理器提供出色的AI每瓦性能,并可支持近2倍数量的虚拟机以及更大规模的大语言模型(例如 Llama 3.2-Vision 11B),从而可推动更先进的AI与混合型工作负载。

并且,新款P100系列处理器支持 AMD ROCm 软件,能够为开发人员和系统设计人员提供可扩展、面向高能效边缘计算解决方案的产品组合。这些处理器支持从视觉到控制到推理的实时AI、提供先进的图形处理能力,同时还支持工业温度范围(−40°C 至 105°C)、7×24 小时连续运行以及 10 年产品生命周期。
分工而非堆砌:AMD的异构计算核心理念
边缘设备工作负载有明显的“混搭”特征,以典型的工业场景为例——设备大部分时间处于低功耗待机,必要时则要瞬间调动高性能算力。这就需要对硬件进行合理分工,高效发挥算力价值。
AMD异构AI加速的核心设计理念,就是通过混合模式的负载分配,实现端到端的AI加速。其中,NPU负责长时间在线的低功耗任务,GPU负责突发的高强度计算,这种方式比一个引擎通吃所有负载更节能、更高效。

AMD采用的是两级唤醒机制的混合负载分配:NPU持续运行物体检测、语音唤醒等低功耗任务,当它检测到特定事件(比如有人进入画面、语音指令被唤醒),GPU接手处理更复杂的任务,包括视频分析、大模型推理等。二者通过统一内存共享数据,不用来回拷贝。通过这样的流程,AMD实现了高效的协同异构,能够在边缘端跑Llama 3.2-Vision这样的大模型。
当然,高效的硬件分工背后离不开合理的软件调度,AMD的做法是:用一套开放的软件栈,把调度复杂性藏在底层。相比于很多芯片厂商要么做封闭生态、绑定开发者,要么做纯开源、不做深度优化,AMD走的是中间路线:上层完全开放,兼容所有主流框架;底层深度优化,释放硬件性能。通过适配开发者熟悉的生态,AMD最大限度降低了使用门槛。

AMD为异构引擎提供优化的AI软件栈包括四层,从上到下分别是:支持从基础模型到定制模型的模型层、为主流开源框架提供全支持的框架层、中间层是包含RYZEN AI和ROCm平台的开发环境,最底层是包括NPU、iGPU在内的硬件层。
这其实也是其异构算力引擎调优的核心所在,AMD为NPU和GPU分别做底层调优,而上层接口是统一的,软件栈会自动把负载分配到合适的引擎。
正是通过紧密的集成,CPU、GPU和NPU架构能在混合工作负载下实现高效的工作负载分配,并确保可预测的时延。在无需额外外部组件的情况下,能够实现先进的计算与图形处理能力,支持OEM厂商和系统集成商轻松设计可扩展的平台。
稳定+无感迁移,嵌入式AI软件栈的双保险
有了良好的硬件组合和高效的软件调度,边缘AI嵌入式平台还面临着两个关键挑战:软件栈的稳定性和平滑部署的实现。
AMD将其数据中心级能力下放,通过支持ROCm 开放软件生态系统,为嵌入式应用带来了业经验证的开源 AI 软件栈。开发人员可以在依赖开源编译器、运行时和库的同时运行标准 AI 框架,并且无需重写代码即可即时访问适用于嵌入式的模型。

开发者最多四步即可完成部署:首先可以继续用PyTorch等现有框架,后端选择AMD iGPU;第二步,从AMD模型库直接获取已适配的嵌入式模型库,比如机器人、工业、医疗等;第三步,编译器处理大部分工作,通过HIP移植CUDA代码(仅需少量修改);如果需要极致性能,第四步再用ROCm工具做内核级优化,进行部署。
通常,对于绝大多数开发者来说,到第一步框架层就结束了,也就是说,他们可以用PyTorch,改一下后端选项,代码就能跑在AMD硬件上。只有少数需要极致性能优化的场景,才需要进入第四步的内核级调优。
通过采用开源的HIP(Heterogeneous-computing Interface for Portability),AMD实现了代码在不同GPU硬件平台之间的可移植性,将 GPU 编程从硬件中解耦,消除了软件栈和硬件之间的供应商锁定,大大降低了开发者的迁移门槛。
落地开始,P100覆盖边缘AI黄金赛道
通过逐代升级,AMD塑造了它在边缘AI嵌入式领域的双重优势:用Zen 5、RDNA 3.5、XDNA 2等消费级IP,给嵌入式产品带来了升级算力;并且具备工业级温度范围、10年生命周期、ECC内存支持,打造了可靠性,而这也正是P100系列的差异化所在。

把最新发布的P100 12核处理器放进AMD嵌入式AI处理器矩阵来看,定位也很清楚:前有6核版本覆盖人机交互的存量市场;后有16核的X100系列为下一代物理AI自主机器人做准备。P100 12核系列居于中间——而这也正是工业自动化最密集、需求最明确的地带,比如工业PC、机器视觉、边缘控制器等。

这其实也反映了AMD的边缘AI布局:用同一架构保证底层的硬件弹性,用户不需要为每个需求重新设计硬件,且产品矩阵至少能覆盖未来三年的边缘AI需求。
从用于智慧工厂的工业 PC到自主机器人和医学成像设备,最新的P100系列针对下一代工业和更广泛的边缘 AI 用例进行了优化。包括:
• 用于工业 PC 的智能机器视觉:新款处理器能实现将可编程逻辑控制器(PLC)、机器视觉与人机界面整合到同一台工业 PC,同时为实时监测与处理优化提供所需的 CPU 性能。集成的 GPU 和 NPU 可加速多路摄像头视觉与丰富的 HMI 仪表板,并支持利用 DeepSORT、RAFT-Stereo、CenterPoint、GDR-Net、PaDiM 和 Llama 3.2-Vision 等模型的低时延异常检测。
• 用于自主运行的物理 AI:针对移动机器人,该处理器可在 CPU 上管理导航、运动控制与路径规划,而 GPU 则处理多路摄像头数据,实现空间感知、Visual SLAM(视觉 SLAM)以及VLA模型等高级 AI 工作负载。CPU 与 GPU 之间的统一内存实现了低时延,从而提升了响应速度。NPU 可提供始终在线的低功耗推理,支持基于 YOLOv12 和 MobileSAM 等模型的目标检测与场景理解。
• 3D 医学成像与临床智能:利用 U-Net、nnU-Net 和 MONAI 等模型,该处理器可在边缘端支持超声、内窥镜、组织分类以及肿瘤检测等 3D 成像。处理器可借助 MedSigLIP 加速从成像到报告的工作流程,并支持通过 Med-PaLM2 实现临床推理与问答能力。医疗领域原始设备制造商(OEM)能在可扩展的长生命周期 x86 嵌入式平台上整合成像、AI 分析与报告功能。
目前,AMD全球ODM伙伴已迅速跟进,初步印证了P100的市场吸引力。
研华科技推出覆盖计算机模块、单板计算机到边缘AI系统的完整产品线,该公司嵌入式物联网事业群副总裁Aaron Su表示,可扩展的P100平台利用增强型集成AI架构可实现高效多任务处理。康佳特产品线经理Florian Drittenthaler则强调,4至12核的可扩展性让客户能精准定制性能、功耗和成本,应对从工业自动化到AI加速的多样化负载。控创基于P100的K4131-Px mITX主板,在紧凑封装内提供4至12核APU,其高级销售与业务发展经理Thomas Stanik将锐龙 AI 嵌入式平台称为“边缘AI驱动型应用的游戏规则改变者”。
写在最后
2026年是工业边缘AI走向规模化的关键年份,AMD在这个时间点推出12核嵌入式处理器P100,不只是一次产品迭代,也是一次精准的战略卡位。它在试图回答业界一个根本问题:当AI从附加功能变成核心能力,工业边缘AI计算平台应该长什么样?
答案不只是一块更快、更强的芯片,更是一条从感知到执行再到决策的演进路径。这条路径上,边缘AI将真正塞进资源受限的设备,依靠可扩展、加速的嵌入式计算平台,支撑起智能自动化、端点智能化和大规模的物理AI应用的落地。
未来几年,会有越来越多的设备在这条路上奔跑,而AMD,正试图做那个铺路人。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...