
随着AI模型参数的膨胀,推理端的成本越来越高,不是每张加速卡都烧得起TSV和硅中介层。
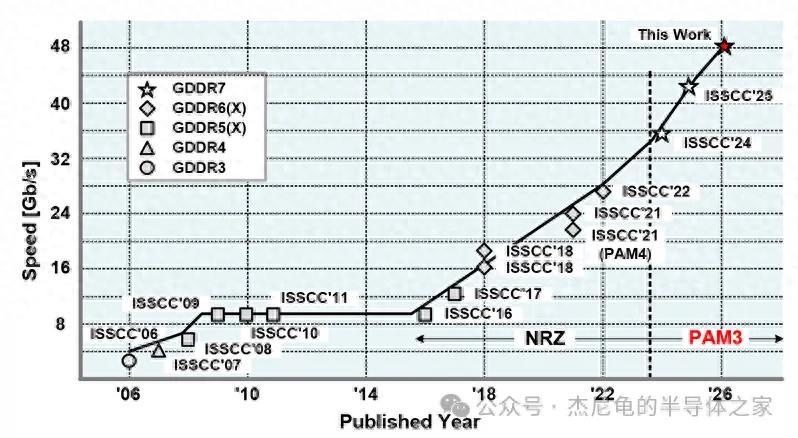
海力士把24Gb的GDDR7推到了48Gb/s,让一个本该降速换容量的2通道模式,跑出了不可思议的性能。
这背后是一套重新设计的对称架构。
AI推理到底需要什么样的内存?
训练要带宽,推理既要带宽更要容量,还得控制成本。
HBM高性能高价格的逻辑,在云端推理规模化部署时不太合适了。针对这一问题,海力士的GDDR7定位很清晰,用单端PAM3信号压低时钟频率和通道损耗,在中端AI推理市场做HBM的平替。
单颗24Gb容量,封装密度直接翻倍
48Gb/s速率,比上一代GDDR6X的峰值更高
2CH架构
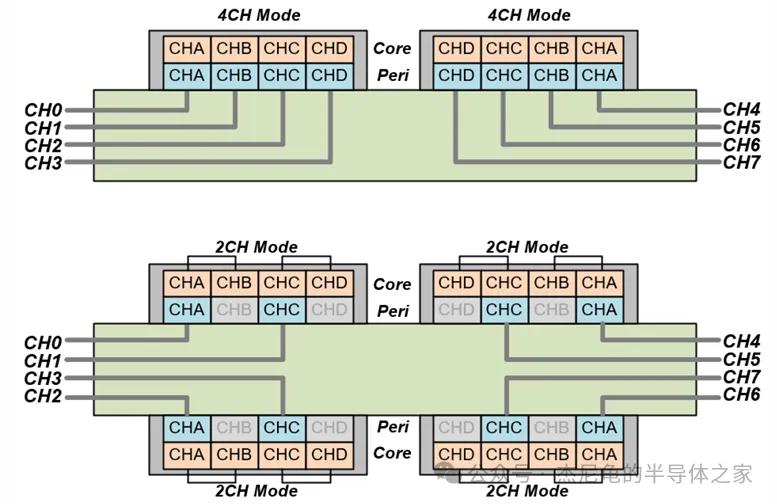
传统GDDR7在2CH模式下有个老毛病,CHB的数据必须绕过外围电路区才能到达接口,导致tAA访问时间比CHA长一截,跨时钟域还容易出现稳定性问题。
海力士的解法很直接,把左右Bank(BKR/BKL)对称摆放,中间塞进4CH/2CH复用器。
数据路径左右对称
中心MUX架构让上下Bank共享最短走线
布线拥堵大幅缓解
时钟路径优化
高频DRAM的瓶颈往往不在晶体管,而在时钟怎么分到每个角落。
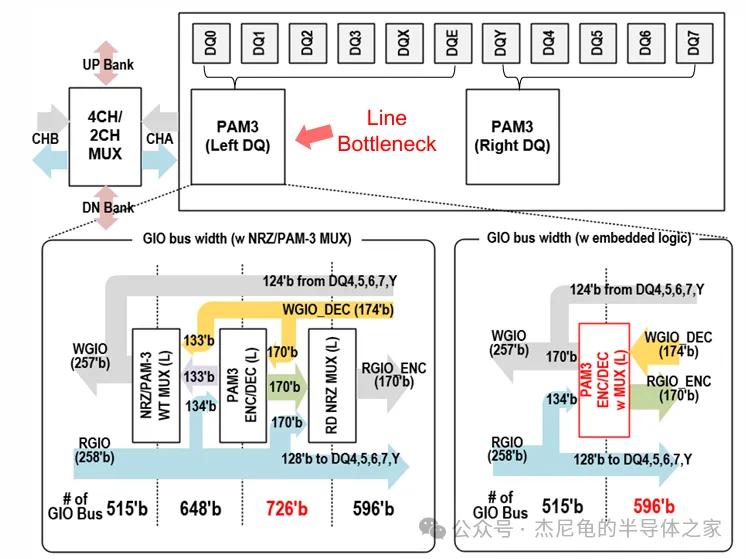
海力士把GIO总线从数据外设区中央挪到了Bank边缘,全局时钟到本地时钟的间隙直接消失。
时钟分布距离缩短20%
本地时钟发生器用CMOS分频器替代传统方案
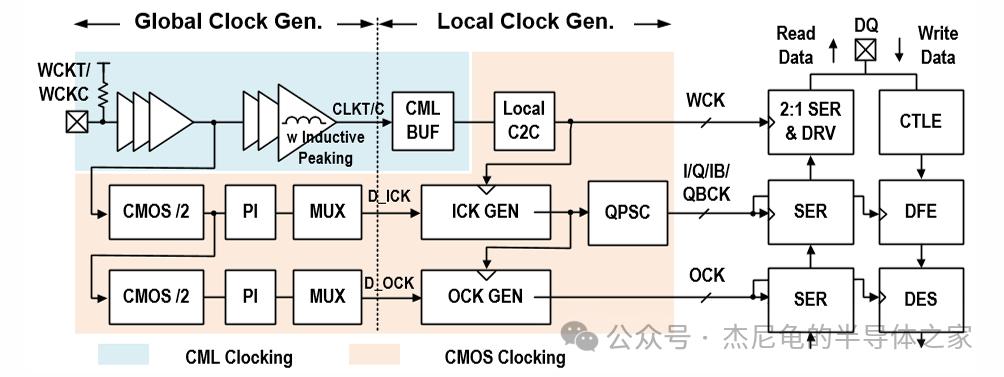
正交相偏斜校正器(QPSC)把I/Q/IB/QB四相时钟的偏斜压到亚皮秒级
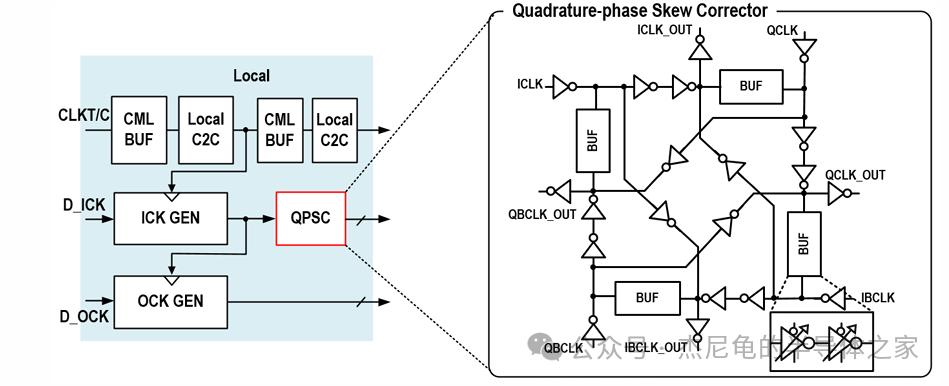
收发器
48Gb/s的单端信号对完整性是非常大的考验。
海力士在TX端塞进了3抽头FFE和AC boosting,用预抽头抵消码间干扰;RX端则采用CTLE配合1抽头DFE,上下两条采样路径独立设置参考电压,还通过额外的时钟偏移补偿(ΔT)把采样裕量拉满。
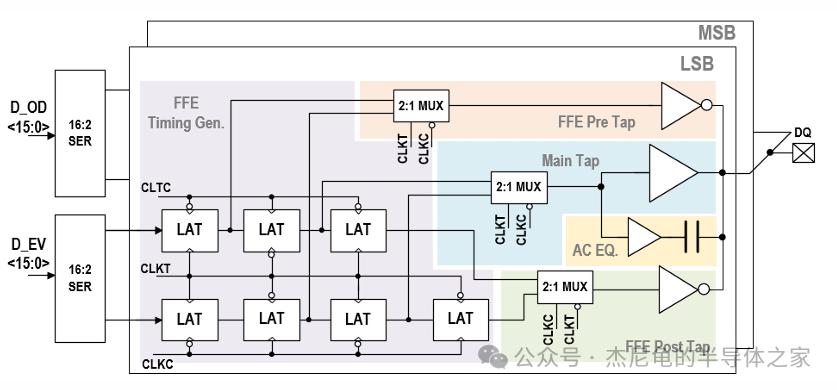
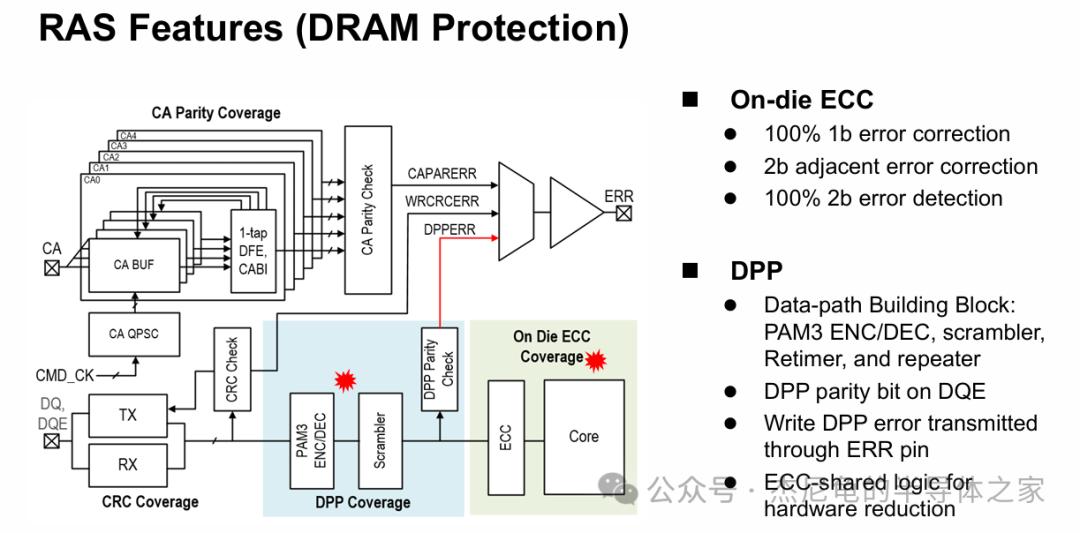
可靠性
链路层
CRC-9覆盖读写,CA奇偶校验阻断错误命令
片内
ECC实现100%单比特纠错、双比特检错,DPP盯着PAM3编解码和扰码器,所有错误统一汇总到ERR引脚,系统侧能实时感知
实测
芯片采用1c nm DRAM工艺,29.10mm²的Die面积塞进266球FBGA封装。实测数据非常完美:
正常模式(VDD=VDDQ=1.2V)直通48Gb/s,1.05V下也能稳在44Gb/s
LVDDQ模式(VDD=1.05V,VDDQ=0.9V)跑出30.3Gb/s
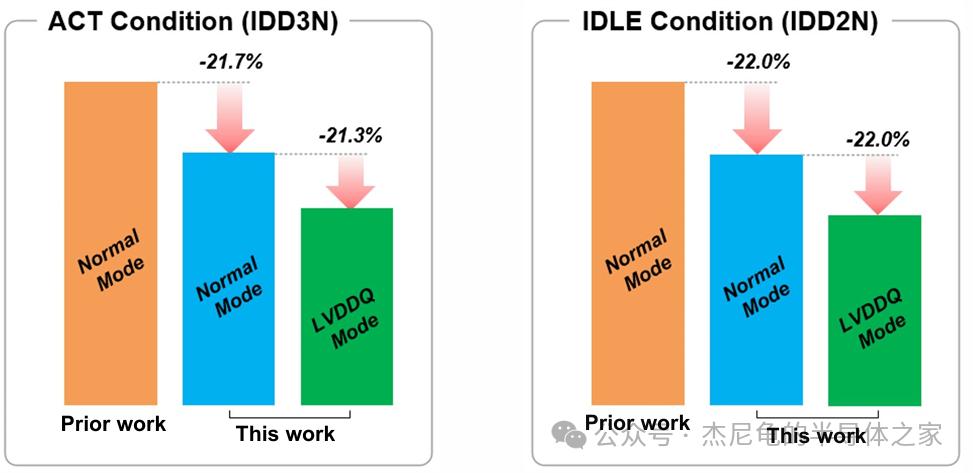
激活态和空闲态功耗同样压低了21%以上
最后,
海力士没有盲目追逐HBM的绝对带宽,而是瞄准了推理场景的真实痛点,这种够快、够大、够省的内存方案,可能比HBM更适合做推理。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...