
我刷到「AMD确认对华出口 MI308,还愿意交15%税」这条的时候,人是懵的。按正常商人思路,这种事不该是能省就省吗,结果人家态度还挺硬气,说准备好了,交。那一瞬间我有种很怪的感觉:这已经不是算账,是抢位置了。
简单一句话先说结论:
15%税费挡不住,AMD这是咬牙砸钱,把中国 AI 市场当生死局来打。
15%“过路费”,AMD还是要硬闯中国

先把事情说清楚。
路透社的消息里,苏姿丰在旧金山参加 Wired 的活动,现场几件事说得很直白:
AMD 已经拿到 MI308 对华出口许可
对华销售要按比例给美国政府交 15%费用
之前那波出口限制,让 AMD 少挣大概 8 亿美元收入
你品一品这个操作:

一边是少掉 8 亿的坑,一边是未来中国 AI 市场的增量,AMD现在的选择其实挺裸的,要么认栽退出,要么掏钱买门票。
更微妙的是,这不是给 AMD 一家量身打造的特殊条款。英伟达那边,H20、L 系列中国特供,圈内也在聊同一件事,大家都得过这个“15%关卡”,就像在中国 AI 市场门口竖了个收费亭,谁想进来做高端算力,先上交一部分利润。

听着有点离谱对吧,但从 AMD 的角度看,这钱不交,损失更大。
算一笔粗账,为什么说“交税也得来”
我自己拿着公开数据扒了一下,很粗糙地算一算:
行价这边,MI308 一块按 1 万美元算没太大问题
每块要拿出 1500 美元去交税

假设一年对华出货 10 万块,税费差不多就是 1.5 亿美元规模
1.5 亿听着吓人,不过看另一边的体量就有点不一样了。
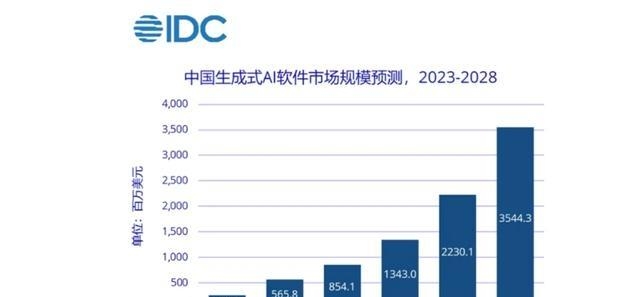
IDC 给过一个预测,中国生成式 AI 相关市场未来几年冲到 300 亿美元级别的规模问题不大,而最贵的那层基础设施,就是算力中心配套的高端 GPU、加速卡。

英伟达这几年把 CUDA 生态、开发者、框架全拴在自己车上,已经坐得非常稳。AMD如果因为出口限制缺席中国,后面 MI 系列再怎么迭代,很可能在全球 AI 数据中心这一块彻底被打成副本角色。
对一家押宝数据中心和 AI 的公司来说,这种场面肯定比交 15%税更可怕。
说难听点,AMD现在是在做一道选择题:
少挣一块钱,保住未来的盘子,还是多留这一块钱,眼睁睁看着中国市场被别人吃干净。
苏姿丰给出的答案已经很明确了。
MI308 是什么水平,不是随便糊弄的特供版
很多人一听“合规版”“对华特供”,下意识觉得肯定是残血货。这个地方得稍微替 MI308 说两句。
根据现在流出来的参数,核心点差不多是这样几条:
算力上
FP8 算力被压在一个安全区间里,刻意避开美国出口红线
跑超大规模训练有点吃力,放到推理、视频分析、智能客服、行业大模型落地这些场景,其实挺对胃口
显存和带宽
高速显存做到了几十 GB 级别,带宽在 TB/s 级别

做大吞吐、低延迟的推理服务,还算是个能打的配置
散热和部署
支持冷板液冷,高密度机柜友好很多
对国内这两年疯狂建的智算中心很对路,能把 PUE 往下压
换句话说,MI308不是“秀肌肉”的那种旗舰怪兽,更像那种在机房里默默扛着大量业务的主力卡。
对国内很多有算力需求的企业呀,真正痛点其实也不在“我要全球最强”,而在“我要这套东西稳定、能耗可控、维护别太折腾、价格别劝退”。MI308这组参数,刚好卡在“够用、可控、不太惹事”的档位。
真正要命的点,在于谁来买单

15%压在头上,钱总得有人掏。
我问了几个做方案集成和渠道的朋友,现在普遍猜法大概是这样:
AMD 自己先把利润砍一部分
中国区价格会上一个小台阶

剩下那一截,从封测、供应链、整机和解决方案打包里抠回来
从用户感知这边,大概会出现几件事:
高端 AI 卡整体价位都不便宜,英伟达、AMD 同梯队都贵
项目立项的时候,预算表里“算力这一行”直接变大块,财务会更加敏感
国产方案突然看起来划算很多,哪怕性能略逊一截,只要稳定可用,采购的心就会缓不少

这个时候,华为昇腾、寒武纪、浪潮信息自研卡、再加一堆本土 AI 加速方案,就会天然多拿到一些“尝试额度”。
你站在技术选型的角度想一下:
之前是“国际大牌便宜又强,我为啥不用”,现在变成“大家都贵,那我给国产多分点量好像也说得过去”,很多公司内部讨论氛围会完全不一样。
AMD看得很明白,得扎根中国,不是路过一下
单靠卖芯片,今天交得起 15%,明年政策一变照样被卡。AMD这一点也想得挺清楚。
圈里传出来的几个动作,其实都指向一个方向:
跟国内服务器厂做深度联合设计,让 MI 系列变成整机标配选项
跟云厂、运营商搞联合实验室,直接在本地做行业方案
建“应用解决方案中心”,把优化、部署、运维团队放在中国
简单讲,硬件是从美国来的,服务和解决方案的触角要扎到中国客户现场。
一旦客户的框架适配、运维体系、监控工具这整套都跟 MI 系列绑在一起,后面不管政策怎么晃,项目不会立刻停摆,AMD跟客户之间的关系也很难一句“换家 GPU”就切干净。
问题在于,AMD的硬伤一直不在算力参数,而在生态。
英伟达这边有 CUDA,当成是事实标准;
AMD 推 ROCm,这两年进步挺快,不过在很多开发团队心里,还是会冒出几个问号:
能不能平滑迁移
实际跑起来会不会各种小坑
出了问题谁来背锅
AMD想在中国市场把 15%税赚回来,单靠 MI308 这块铁,远远不够,得用大量本地项目一点点把这些问号变成“可接受”。
美国加税,反过来可能帮国产拉开距离
这事对国内还有个挺有意思的反作用。
美国那边想卡高端算力,对英伟达、AMD加税、限性能,看起来是在收紧。结果在中国这边的实际效果,很可能是:
顶级卡越来越贵,越来越稀缺
国产中高端卡拉着国际大牌打“性价比战”
大量行业项目被迫学习怎么在国产生态里跑通
你细想一下,这其实反而给了本土厂商一个挺宝贵的窗口期。
以前很多甲方一上来就一句:“按业界最通用那套来,直接上英伟达吧。”
未来很可能变成:“核心业务先上最稳的,剩下这些项目试试国产,看行不行。”
国产要做的事也很清楚:
把编译器、算子库、调优工具这些东西打磨扎实,多丢出一点真实的成功案例。只要能撑过这几年窗口期,等生态稍微站稳,高端算力就不是永远属于别人家的游戏。
我个人一点小感受,你呢?
我看完这件事,心情挺复杂的。
一边觉得 AMD 这波有点惨,辛苦研发出来的高端 AI 卡,还得先被自己国家政府薅一把羊毛,想进中国市场都要先交“过路费”;
另一边又不得不承认,对中国这边用户和产业,短期还真未必是坏消息:
多了一个有竞争力的选项,至少不至于被某一家卡脖子卡到窒息
国际厂商被迫涨价,本土厂商反而更容易被认真对待,不是永远当“备胎方案”
未来两三年,国内 AI 算力生态的成长速度,可能会比很多人预期更快
那问题就丢给你了。
如果你现在是公司技术负责人,手里能选的有英伟达、有 AMD,还有华为昇腾、寒武纪这一堆国产卡,你会怎么搭配?
关键业务一边倒押在 CUDA 上,还是尝试搞个“混搭架构”,给国产多一点试错空间?
更想听听,你或者你身边的公司,在 AI 算力采购上有过什么翻车故事或者惊喜体验,欢迎直接在评论区讲讲,后面我可以专门拉一篇,把这些一线实战经历好好盘一盘。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...