在犯错之后,会出现一个恶性循环;但当你设法把自己从坑里挖出来,不仅不再犯错,还通过优秀的工程能力、辛勤的工作以及一点运气赶上并超越竞争对手时,也会出现一个良性循环。
过去十年里,由于(主要是代工业务的失误)英特尔在数据中心领域表现挣扎,这对AMD来说并非坏事;就像在那之前的十年里,AMD自己一路“跌下楼梯”时,也并没有伤害到英特尔一样。由于多个问题,AMD在十年前几乎被数据中心市场彻底赶尽杀绝,不得不重新赢得CIO们的信任,几乎像一家创业公司一样重头再来——先是依靠CPU,如今又凭借GPU以及借助其对赛灵思(Xilinx)、Pensando 和 ZT Systems 的收购而获得的部分网络和系统设计能力。
现在,AMD首席执行官苏姿丰(Lisa Su)以及其核心管理团队表示:AMD已经准备好乘上AI浪潮,并在传统企业级计算市场中获取超过其应得份额的增长。
这正是本周在纽约举行的面向华尔街的金融分析师日(Financial Analyst Day)上传达的主要信息。AMD并不经常举办这种FAD活动,因此每一次都对帮助外界同步预期、微调预测具有重要意义。第一次FAD是在2009年举办,那一年英特尔的Xeon产品线表现极佳,而AMD的Opteron表现不佳。2012年,前任CEO Rory Read 举办了一次大型FAD,宣布公司将弱化其数据中心业务;但到了2015年,苏姿丰成为CEO,技术长Mark Papermaster发布了AMD的“Zen”架构以及在数据中心实现复兴的目标。2017、2020、2022以及2025年的FAD活动则分别勾勒了这条复兴路线上的里程碑。如今可以安全地说:在高性能CPU和GPU方面,AMD已经比其老对手英特尔更可靠;同时在GPU与DPU方面成为Nvidia可信的替代者,并且从明年起,也将成为机架级AI系统的一个可行竞争者。
我们花了几天时间反复研究FAD 2025近五小时的演示内容,现在很高兴能根据本周AMD高层发表的内容,并结合我们对Nvidia的预期,分享我们自己的模型分析。
接下来是AMD对数据中心可寻址总市场(TAM)的最新界定,以及公司对自身CPU与GPU计算产品在该总体TAM中表现的评估——需要强调的是,这里的TAM指的是销售到数据中心的芯片本身,而不是由这些芯片构建的系统,也不包括将软件叠加其上所形成的完整解决方案。AMD销售芯片并免费提供软件,因此它统计的内容包括CPU、GPU(含其转售的HBM内存)、DPU、机架级系统的scale-up网络,以及scale-out网络中的DPU。
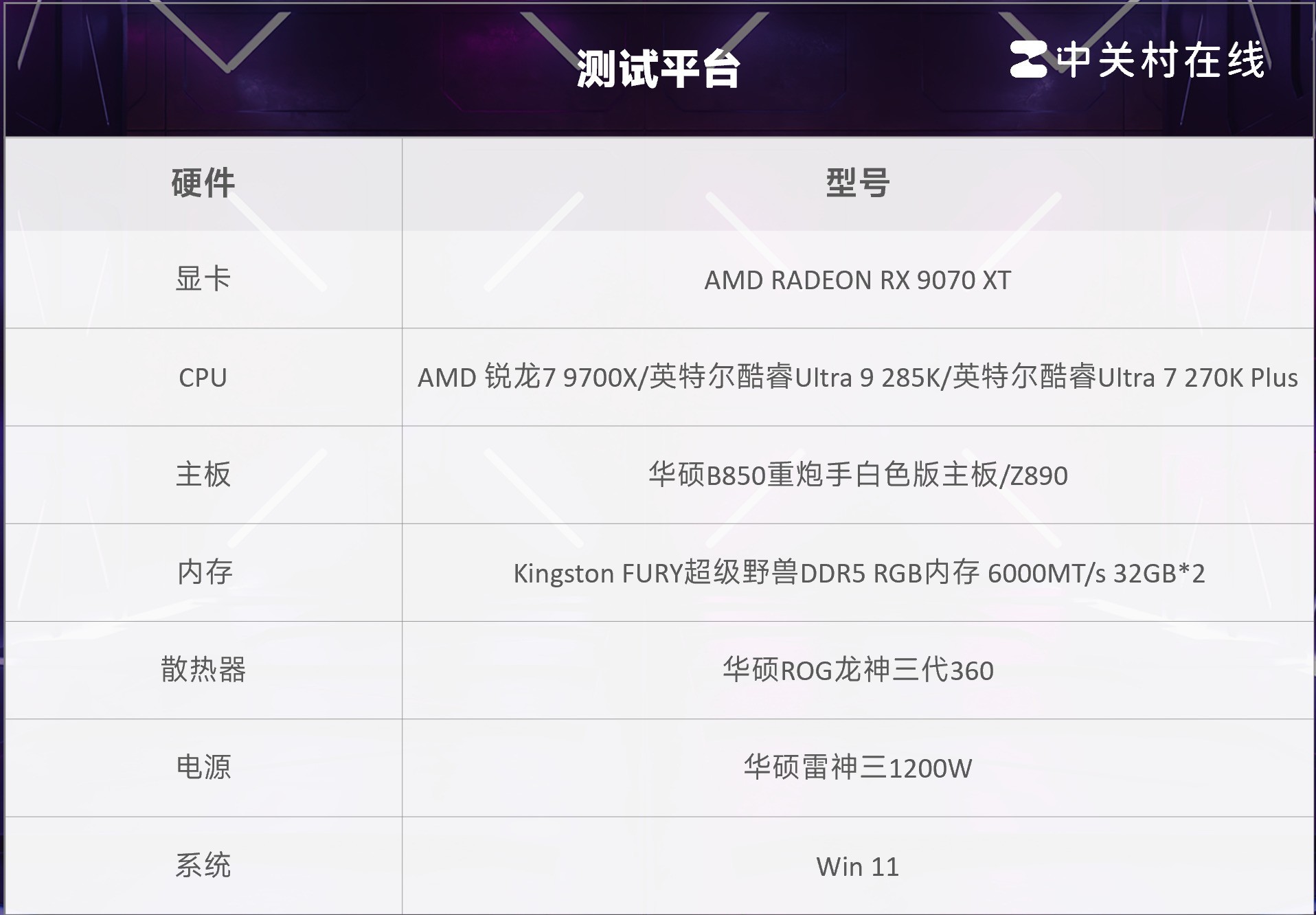
直到目前为止,苏姿丰及其团队提供的TAM和预测仅针对数据中心AI加速器。供您参考,这是过去两年内所有的预测:
我们在今年6月做过大量“巫术般的分析”,试图将AI训练芯片与AI推理芯片区分开来,再进一步推算AI推理与训练系统的收入规模。以红色粗体与蓝色斜体标出的数字为 The Next Platform 为填补模型空白或进一步限定AMD TAM模型而做出的估算。
而这一次,在FAD 2025上,AMD只讨论整个数据中心市场,并向华尔街说明其CPU和GPU业务未来将会如何表现。以下是苏姿丰公布的最新数据中心TAM图表:

“要准确判断TAM是什么,总是非常困难。”苏姿丰在开场白中承认。“当我们最早开始讨论AI TAM时,我记得我们从3000亿美元开始,后来更新到4000亿美元,再到5000亿美元。我记得你们中很多人都说过:‘Lisa,这个数字也太高了吧?你为什么认为这些数字会这么高?’事实证明,就AI加速的速度而言,我们可能比错误更接近正确。而这些判断来自我们与大量客户的深入讨论——了解他们如何规划自己的计算需求。”
因此,这就是AMD以及在很大程度上Nvidia正在追逐的TAM。(Nvidia的TAM更大一些,因为它还销售数据中心的scale-out和scale-across网络。但我们暂且忽略这一点。)
“毫无疑问,数据中心是当前最大的增长机会,而AMD在这个市场中的位置非常非常有利。”苏姿丰继续说道。“我真正想强调的是,我们的战略一直非常一致。我认为在科技行业必须如此,因为坦白讲,这些产品周期都非常长。这些是我们的战略支柱:我们从计算技术领先开始,这是一切的基础。我们极度专注于数据中心领导力,而数据中心领导力涵盖芯片、软件以及随之而来的机架级解决方案。”
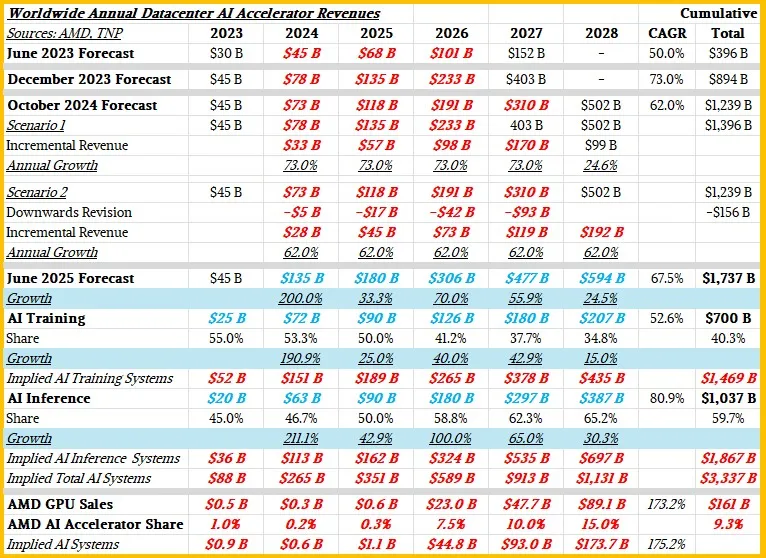
在她的演讲中,苏姿丰表示:未来三到五年间,AMD的数据中心AI收入将实现超过80%的复合年增长率(CAGR);在同一期间,公司将有望在服务器CPU市场获得超过50%的营收份额、在客户端CPU获得超过40%的营收份额,并在FPGA市场获得超过70%的营收份额。她还表示,AMD数据中心部门在未来三到五年将实现超过60%的CAGR;而其核心客户端、嵌入式、定制和FPGA业务将在同一期间实现10%的CAGR,从而推动AMD整体营收实现超过35%的CAGR。最后,苏姿丰表示,AMD预计2025年营收约340亿美元,其中约160亿美元将来自数据中心部门;我们认为今年其Instinct数据中心GPU将实现约62亿美元营收,Epyc服务器CPU约93亿美元营收,剩下一小部分来自DPU和FPGA。
在将所有数字塞入“魔法电子表格”之前,我们先来讨论一下CAGR。所谓CAGR,就是取一个数据集的两个端点,然后画一条直线,并计算这条直线的斜率。这是一个非常粗糙的工具,完全忽略了任何市场自然存在的高峰和低谷。特别是在AI领域,我们认为——苏姿丰也同意——未来几年的增长会高于后期年份。我们也认为2026、2027以及2030年将是AI市场整体增长非常好的年份。我们的模型反映了这一点。
因此,不再赘述,这里是AMD模型;而为了比较,我们也加入了日历化的Nvidia数据中心销售额。(注意:Nvidia的财年截至1月,因此需要将N、N-1、N-2三个财年中的1月营收剔除 N 年、从 N-1 中剔除、并将 N-2 的1月加到 N-1 中,以得到当前自然年的营收估算。)请看下方:
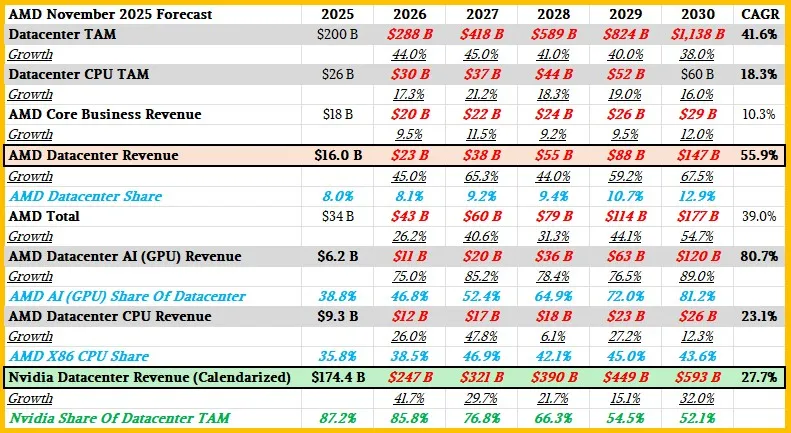
一些观察:在假设AMD数据中心营收实现60% CAGR 的情况下,又要让AMD总体营收保持在35% CAGR,同时让其核心业务(PC、嵌入式、FPGA)保持10% CAGR,从数学上似乎很难同时成立。我们的模型尝试平衡这些因素,同时让数据中心AI市场的机会在预测期末仍保持超过1000亿美元。
让我们继续讨论CPU业务。在深入表格前,先提一下AMD计算与企业AI总经理 Dan McNamara 对2026年即将发布、基于Zen 6与Zen 6c内核的“Venice” Epyc处理器规格的介绍:

根据“线程密度”的说法,我们计算得出的倍数为1.33,从而对应Zen 6版本为172核心,Zen 6c(半缓存版本)为256核心。而Zen 5版本的“Turin”Epyc 9005系列最高为128核心,Zen 5c为192核心。
McNamara展示的另一张有趣图表来自AI工作负载推动的GPU需求反过来刺激服务器CPU市场的复兴:
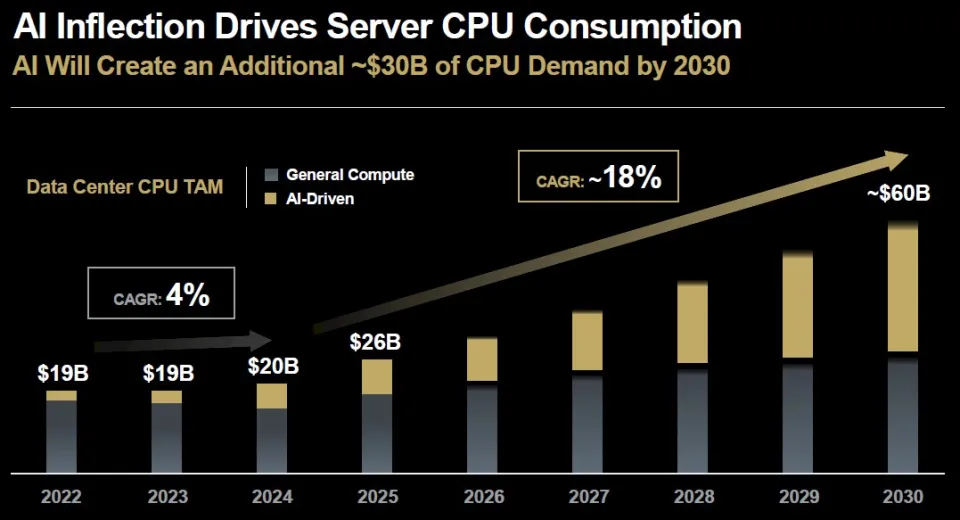
我们已经说了一段时间:如果把AI系统剔除,一般用途服务器市场实际上处于衰退——而从以上数据可以清楚看到确实如此:2022至2023年间,只有用于AI系统的高端服务器CPU维持了市场的平稳;而2024年一般用途服务器营收下降得更快,却依然因AI系统CPU销售而获得支撑。(我们认为在系统营收层面也是类似趋势,而且因为每套系统中GPU数量更高且单价更高,影响会被放大。)
今年,由于大量老旧机器需要升级,并通过负载整合提升效率、释放电力、空间与预算用于AI系统,一般服务器市场(以及其CPU部分)重新回升,AMD预期这一市场将增长到2030年。而AI服务器CPU市场将从2025年约82亿美元增至2030年约300亿美元——以服务器CPU标准来看,这是极其巨大的增长。
重点是:AI工作负载仍然需要大量串行处理,并且需要快速而昂贵的处理器来完成这些工作。
在GPU方面,AMD 的 MI350 与 MI355X GPU 正在加速量产,但所有目光都集中在明年推出的 MI400 系列——这些GPU将插入AMD与Meta合作打造的“Helios”机架中。同时,有不少人也在关注2027年推出、搭载 MI500 系列的新一代机架。
以下是“Altair”MI450 系列的基础规格,我们给它命名 Altair,因为AMD拒绝为其GPU正式采用代号:

虽然 FP4 和 FP8 精度下的FLOPS 很重要,但更重要的也许是HBM4内存的容量与带宽。我们认为,这意味着FP16训练将获得所需的内存容量与带宽,使其效率大幅优于以往的GPU;而在FP8与FP4模式下,也会有足够的带宽让上下文tokens更快被处理、输出tokens更快生成,相比Nvidia和AMD此前乃至当前GPU都更快。
据我们了解,MI400系列共有三种型号,全部采用台积电2nm(N2)工艺。正如苏姿丰本周指出,这是全球首批采用该工艺的芯片。MI450 面向 Microsoft 与 Meta 推动的 OAM 八路开放主板;MI450X(上图)进入 Helios 机架,初始为72 GPU 的配置(类似Nvidia “Oberon” 中的 NVL72),也将提供64与128 GPU 的版本。MI455X 是高端型号,我们认为其HBM4容量为432GB——明显高于今年早些时候提到的288GB。
配备 MI455X 的 Helios 机架可提供 1.45 EFLOPS(FP8)与 2.9 EFLOPS(FP4),总计31TB HBM4、以及1.4PB/s 带宽。其基于以太网的UALink(UALoE)scale-up网络可为72颗GPU提供260TB/s的带宽(每颗3.6TB/s),机架外的scale-out网络带宽为300GB/s。
以下是AMD将其未来Vera-Rubin 计算引擎(用于Oberon机架)与 Venice-Altair 计算引擎(用于Helios机架)进行对比:
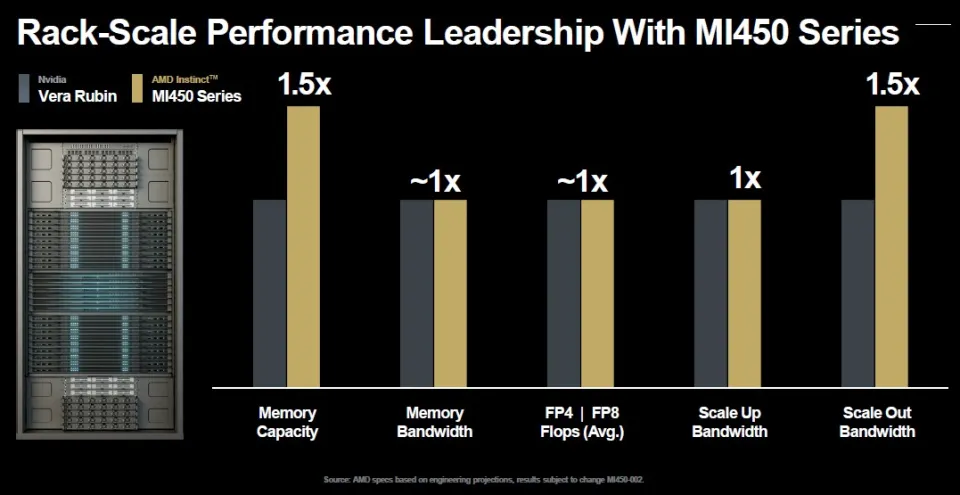
看起来势均力敌……
MI430X 是 Altair 的另一个型号,目前信息不多,它面向逐渐成为AI中心的国家级HPC中心:

我们强烈认为 MI430 将拥有更高的FP64性能密度(每单位能耗或每美元),但AMD如何实现仍不得而知。今年早些时候,我们与 AMD GPU平台副总裁、长期领导IBM Power CPU项目的 Brad McCredie 对话时,他曾暗示AMD正在尝试一些新设计。我们当时提出:是否可以将不同浮点精度拆分到不同计算chiplet中,例如FP64/FP32一个chiplet、FP16一个chiplet、FP8一个chiplet、FP6/FP4一个chiplet,并将向量与Tensor单元也拆成独立chiplet。他暗示AMD正在做一些类似的事情,但没有给出细节。
最后是机架级GPU系统的短期路线图:

随着“Verano”Zen 7/Zen 7c处理器的推出,AMD也将发布MI500系列GPU——我们还没有为其想好代号,以便让AMD自己先公布。同时AMD会继续沿用“Vulcano” DPU 系列作为Helios机架的组件。
AMD尚未透露太多MI500的信息,但以下是相对性能路线图:
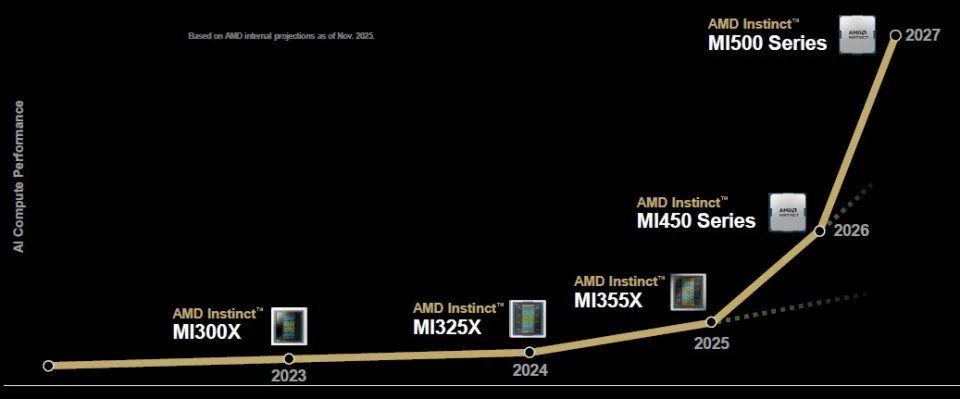
如果该图按比例绘制,则MI500系列最高将达到约72 PFLOPS(FP4),比MI455X高约80%,是正在量产的 MI355X 的7.8倍。
企业确实是“购买路线图,而不是购买单点产品”,但最终仍必须购买某个实际产品才能完成实际任务。买家总是希望等待下一代计算引擎来获得更高效率,但如果一直等待,工作永远无法完成。AMD、Nvidia 等厂商当然能依赖这种心理——并顺利将其转化为收入。
只要看看我们上文模型中 AMD 与 Nvidia 的收入数字,就知道这个市场有多丰厚。
参考链接
https://www.nextplatform.com/2025/11/14/amd-solid-roadmaps-beget-money-which-beget-better-roadmaps-and-even-more-money/
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...